The Volume Hypothesis And Sharp Minima
This blog post is for our paper, “Sharp Minima Can Generalize: A Loss Landscape Perspective On Data”. Here, we introduce background for our paper and briefly summarize our key results. Experiments are explained in greater detail in our work, along with many other insights.
A video overview is also available.
For those interested in running their own experiments, here is a tutorial in google colab.
Introduction
Classical learning theory (eg, PAC-Bayes
But neural networks have tons of parameters. They can produce arbitrarily complex models that memorize the data (“overfitting”).
And yet in practice, they do well. We train them with gradient descent, and we consistently end up with solutions that generalize well.
To explain this phenomenon, Huang et al. came up with the volume hypothesis
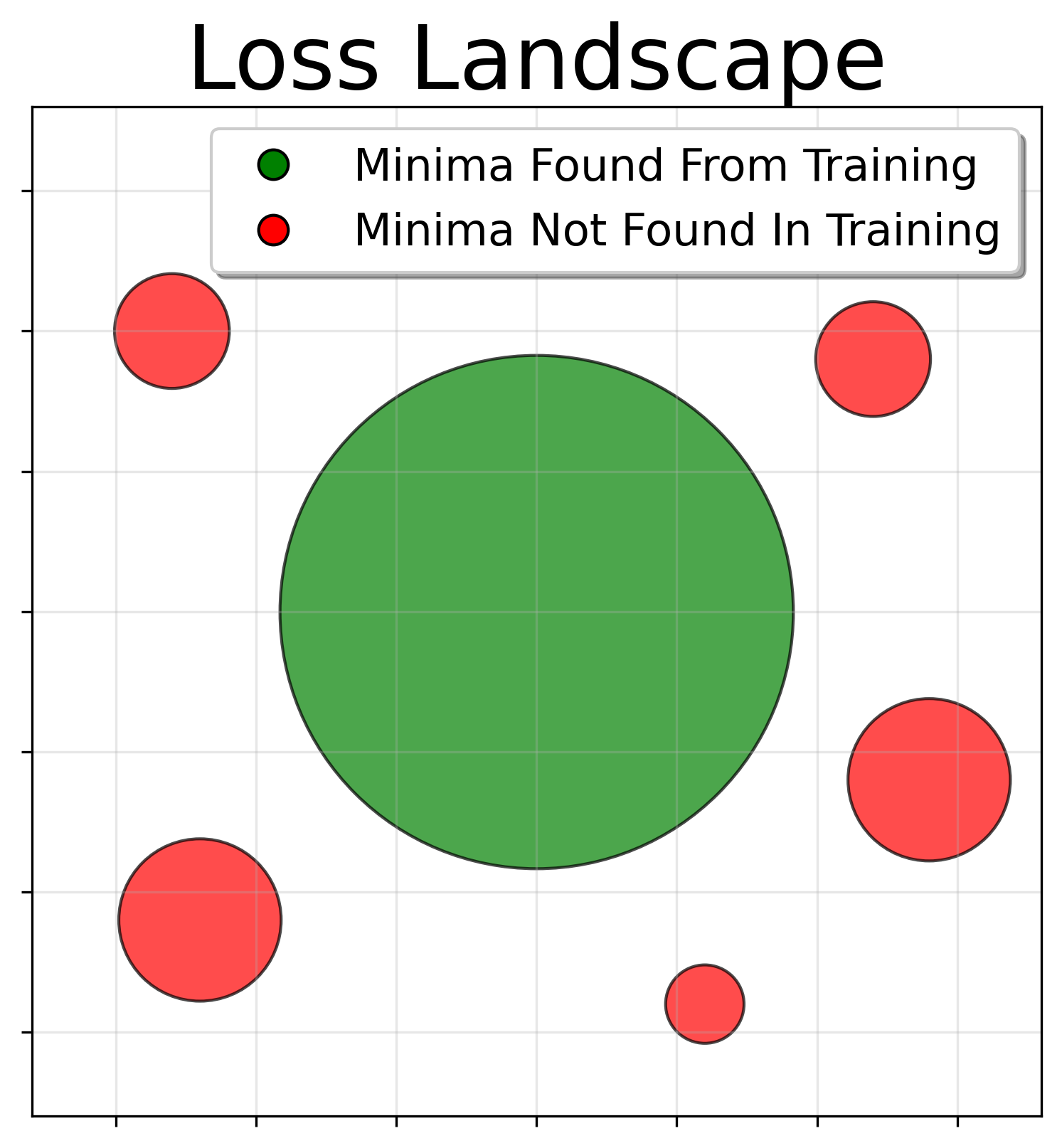
How would this explain generalization? There’s a conjecture called the flat minima hypothesis, which argues that minima which are flat in parameter space generalize better
Testing The Volume Hypothesis
These two hypotheses can be tested experimentally: if we acquire a variety of minima, evaluate their volumes on a dataset and their test accuracies, we should find
- Minima found from gradient descent on the dataset occupy the largest volumes (volume hypothesis)
- Large volume minima have better test accuracy (flat minima hypothesis)
How do we define volume of a minima? If we have a minima, we can change its parameters by a small amount which changes the loss as well. The volume of a minima is the region of connected parameter space which lies below some loss threshold. This volume is easy to estimate via a Monte Carlo technique, although it has some shortcomings (see our paper).

Volume is thus a measure of minima flatness that is directly proportional to the probability of finding a minima via randomly chosen parameters, which is useful for some experiments
Using this measure of volume, Huang et al. (as well as others
Therefore the volume hypothesis is a plausible explanation for why we don’t observe these poorly behaved minima in practice.
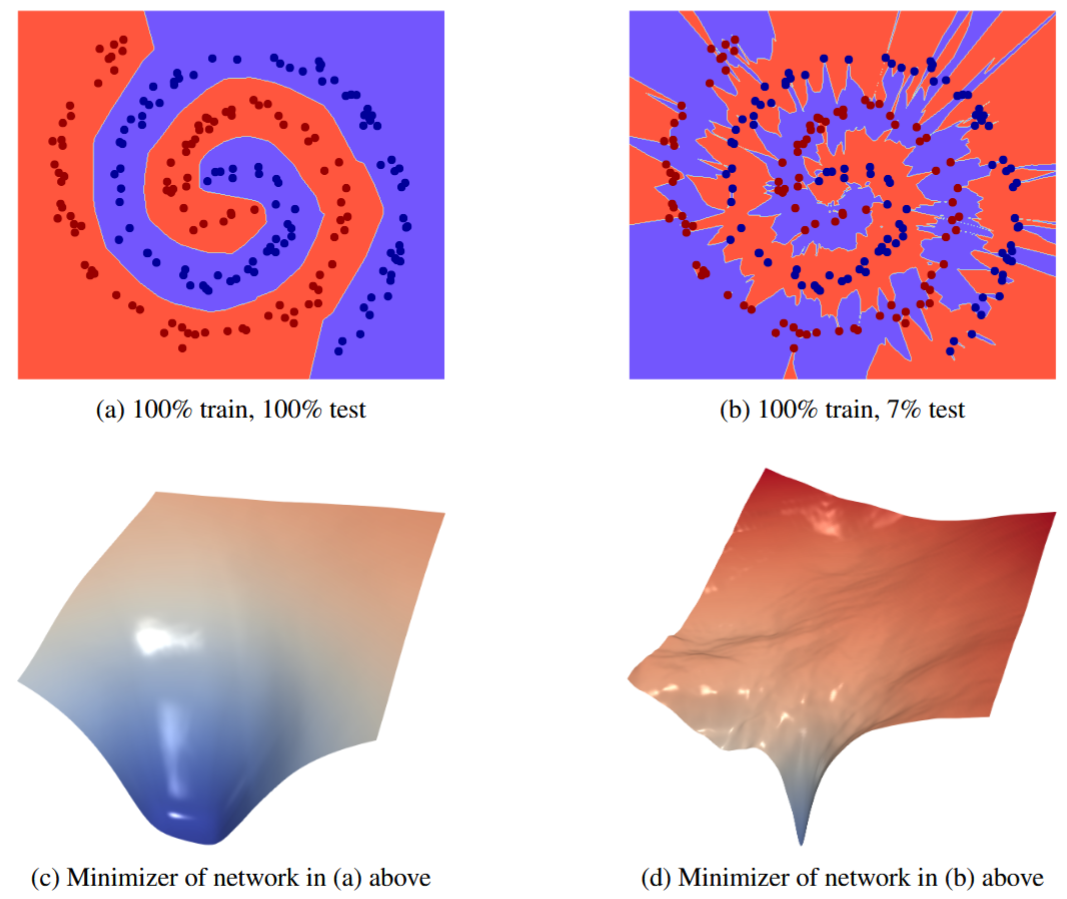
What About Data?
The above results paint a very idealistic picture of deep learning:
- Volume hypothesis guarantees we find large volume minima
- Flat minima hypothesis implies the large volume minima generalize well
This picture ignores that large datasets are needed in deep learning. So one of these hypotheses must break down in small datasets.
Note that flatness measures (eg, volume) are measured with respect to a given dataset. Maybe in small datasets we don’t tend to find large volume minima, or large minima in small datasets don’t generalize well. Our experiments suggest the latter is true.
Our Experiments
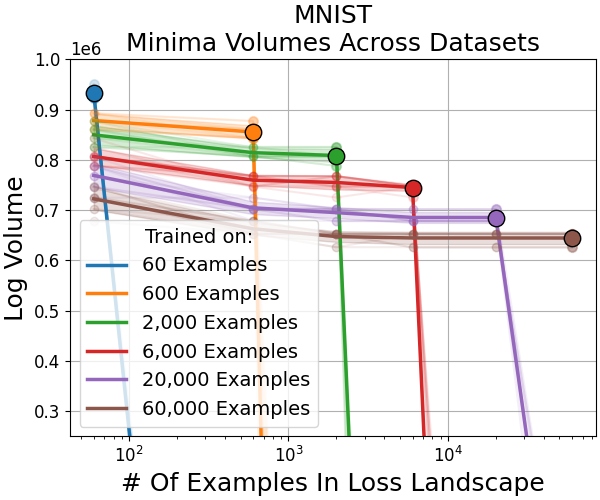
We train minima on larger and larger subsets of a problem (eg, MNIST). This gives us a variety of minima, and a variety of datasets to evaluate their volumes on. We find that for small datasets:
- Minima found from gradient descent on the dataset are larger in volume than minima from training on larger datasets.
- Minima which generalize best have very small volumes.
The volume hypothesis seems to accurately describe the minima found by deep learning even at small datasets - the minima we get occupy much larger volumes. Meanwhile the flat minima hypothesis doesn’t seem to hold very well - minima we get from larger dataset sizes (which have better test accuracy) are sharp.
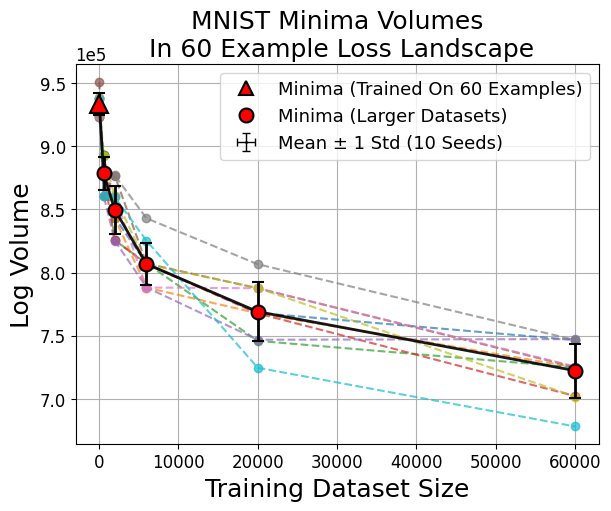
Do our results only hold for small datasets? For MNIST and CIFAR10 (see paper), the opposite seems to be true - there seems to be a power law between minima volume and dataset size that suggests larger and larger datasets find smaller and smaller minima.
Adding more data shrinks the previously large minima, such that (previously small) minima are now the largest in the new loss landscape formed by more data. This explains why we find them now, from a volume perspective.
Other Results
Aside from our main results here - showing counterexamples to the flat minima hypothesis, while the volume hypothesis appears robust - our paper also contains a number of other experiments and observations. Notably:
- Minima tend to shrink with more data. There is no obvious trend for how they shrink - flat minima can abruptly disappear as more data is added, while some sharp minima remain.
- Poisoning the dataset reduces the size of the found minima much faster than adding properly labelled additional data. This suggests most sharp minima are bad.
- Using sharpness-aware minimization results in slight increases in both volume and test accuracy
. - Grokking, the phenomenon where test loss abruptly shrinks long after train loss appears to plateau, seems easily explainable from volumes
. We find a surprising result where systems that grok initially find a large volume solution (with high test loss) and then slowly find a much sharper minima with very low test loss. This is another striking counterexample to the flat minima hypothesis.
Future Outlook
Our results add evidence to existing work suggesting minima flatness is not essential for generalization
This raises a crucial question:
Should future work prioritize minima flatness in search of data-efficient algorithms for deep learning?
The experiments that re-motivated the flat minima hypothesis studied improved generalization with small-batch training
Probing deeper into theoretical explanations for the flat minima hypothesis, the most common is a complexity argument - a minima which is flat, can stored in less bits and is thus lower in complexity
For examples, see the simple analytic solutions obtained from grokking
As a final point, we note while the trends may be unclear, there does not seem to be any flat minima which generalize as well as the sharp minima. Our results suggest the large data-driven models of today are in some sense ‘sharp’, and adding more data to improve them only results in even sharper minima.
Given that we have no evidence of the hypothetical existence of very flat and very good minima, it may be time to consider approaches aside from flatness.